메모리 계층
CPU는 그저 메모리에 올라와 있는 프로그램의 명령어들을 실행할 뿐
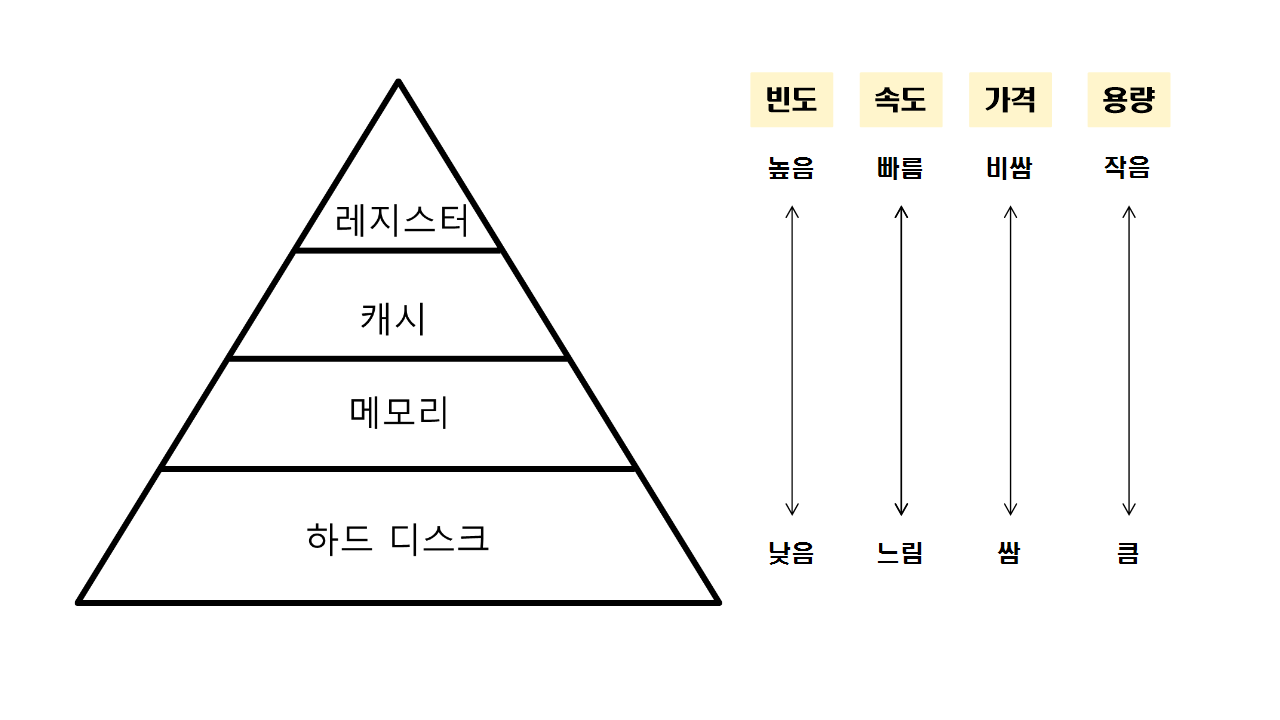
레지스터 : CPU 안에 있는 작은 메모리,휘발성, 속도 가장 빠름, 기억 요량이 가장 적음
캐시 : L1, L2 캐시를 지칭합니다. 휘발성, 속도 빠름, 기억욜야이 적고 L3 캐시도 존재합니다.
주기억장치 : RAM을 가리킵니다. 휘발성, 속도 보통, 기억 용량이 보통입니다.
보조기억장치: HDD, SDD를 일컬으며 휘발성 속도 낮음, 기억용량이 많습니다.
캐시 (cache)
캐시는 데이터를 미리 복사해 놓는 임시 저장소이자 빠른 장치와 느린 장치에서 속도 차이에 따른 병목 현상을 줄이기 위한 메모리를 말함
실제로 메모리와 CPU 사이의 속도 차이가 너무 크기 때문에 그 중간에 레지스터 계층을 둬서 속도 차이를 해결합니다.
이렇게 속도 차이를 해결하기 위해 계층과 계층사이에 있는 계층을 캐싱계층이라고 함
예를 들면 캐시 메모리와 보조기억장치 사이에 있는 주기억장치를 보조기억장치의 캐싱계층이라고 함
- 지역성
- 데이터 접근이 시간적, 혹은 공간적으로 가깝게 일어나는 것
- 캐시가 효율적으로 동작하기 위해서는 캐시가 저장할 데이터가 지역성을 가져야 함
- 종류
시간적 지역성 특정 데이터가 한 번 접근되었을 경우,
가까운 미래에 또 한 번 데이터에 접근할 가능성이 높음공간적 지역성 액세스 된 기억장소와 인접한 기억장소가 액세스 될 가능성이 높음
캐시히트(cache hit) , 캐시미스(cache miss)
캐시히트 : 캐시에서 원하는 데이터를 찾았다하면 캐시히트,
캐시미스 : 해당 데이터가 캐시에 없다면 주 메모리로 가서 데이터를 찾아오는 것을 캐시미스

캐시매핑
캐시 매핑이란 캐시가 히트되기 위해 매핑하는 방법을 말하며 CPU의 레지스터와 주 메모리(RAM) 간에 데이터를 주고 받을때 기반으로 설명, 레지스터는 주 메모리에 비하면 굉장히 작고 주 메모리는 굉장히 크기 때문에 레지스터가 캐시 계층으로 역활을 잘해주려면 이 매핑을 어떻게 하느냐가 중요
캐시 매핑분류
1. 직접매핑(Direct Mapping)
메모리 주소와 캐시의 순서를 일치시킨다. 메모리가 1~100까지 있고 캐시가 1~10까지 있다면 1~10까지의 메모리는 캐시의 1에 위치하고 11~20까지의 메모리는 캐시의 2에 위치시키는 것이다. 구현이 정말 간단하지만 저 규칙을 만족시켜서 캐시를 넣다 보면 캐시가 효율적이지 않게 자꾸 교체되어야 하는 일이 생긴다.
예를 들면 30~40에 해당하는 값을 자꾸 불러다 사용해야 하는데 이를 저장할 캐시 공간은 3 하나 뿐이므로 매번 캐시 교체가 일어나게 된다. 즉 적중률이 낮고 성능이 낮은 단순한 방식이다.
2. 연관매핑(Associative Mapping)
순서를 일치시키지 않는다. 필요한 메모리값을 캐시의 어디든 편하게 저장 될 수 있다. 당연히 찾는 과정은 복잡하고 느릴 수 있지만 정말 필요한 캐시들 위주로 저장할 수 있기 때문에 적중률은 높다. 캐시가 일반 메모리보다 속도가 훨씬 빠르므로 캐시의 검색량을 신경쓰는 것 보단 적중률이 높은게 성능이 더 좋다.
3. 직접연관매핑(Set Associative Mapping)
연관매핑에 직접매핑을 합쳐 놓은 방식이다. 순서를 일치시키고 편하게 저장하되, 일정 그룹을 두어 그 그룹 내에서 편하게 저장시키는 것이다. 예를 들면 메모리가 1~100까지 있고 캐시가 1~10까지 있다면 캐시 1~5에는 1~50의 데이터를 무작위로 저장시키는 것이다. 블록화가 되어 있기 때문에 검색은 좀 더 효율적으로 되고 직접매핑처럼 저장위치에 대한 큰 제약이 있는건 아니기 때문에 적중률이 많이 떨어지지도 않는다.
출처: https://raisonde.tistory.com/entry/캐시-메모리-매핑-기법 [지식잡식:티스토리]
'Computer Science > 운영체제' 카테고리의 다른 글
| 스레드 & 멀티스레드, 공유자원 (0) | 2022.06.24 |
|---|---|
| 프로세스와 스레드 (0) | 2022.06.18 |

